Events are essential to ModeShape. When your application saves changes to content, ModeShape generates events that describe those changes and sends those events to all of your applications’ listeners registered. The bottom line is that every listener is able to see events for all of the changes made, regardless of which part of the cluster those changes were made or in which part of the cluster your listeners are in.
But your applications aren’t the only components that respond to events: ModeShape itself has quite a few listeners that allow it to monitor and react to those same changes. Some of ModeShape’s listeners respond to changes in your content, while other internal listeners respond to changes made by ModeShape. How? ModeShape stores all kinds of system metadata in the repository (namespaces, node type definitions, locks, versions, index definitions, federated projections, etc.). When any of this metadata is changed and persisted on one process in the cluster, it is only via events that all of the other processes in the cluster notice these changes.
For example, when your application registers a new namespace prefix/URI pair, ModeShape reflects this in the local NamespaceRegistry instance’s in-memory cache and immediately persists the information. But what about the NamespaceRegistry instances elsewhere in the cluster? They’re using listeners to watch for changes in the namespace area of the system metadata, and as soon as they see an event describing the new namespace, the (remote) NamespaceRegistry instances can immediately update their in-memory cache so that all sessions throughout the cluster see a consistent set of namespace registrations.
ModeShape has quite a few components that use events in a similar way: indexes, locks, versions, workspace additions/removals, repository-wide settings, etc.
The ChangeSet and ChangeBus
To register a listener, an application must implement the javax.jcr.observation.EventListener interface and then register an instance with the workspace’s ObservationManager. Standard JCR events can describe the basics of when nodes are created, moved or deleted, and when properties are added, changed or removed. But that’s about it.
Internally, ModeShape uses a much richer and finer-grained kind of events. Every time that a transaction commits (whether that includes a single session save or multiple saves), descriptions of all of the changes made by that commit are bundled into a single ChangeSet. It is these ChangeSets that ModeShape actually ships around the cluster, and all of ModeShape’s internal components are written to respond to them by implementing and regsitering an internal ChangeSetListener interface. Interestingly, every time your applications register a new EventListener instance, ModeShape actually registers an internal ChangeSetListener implementation that merely adapts each ChangeSet (and the changes described by it) into a standard set of JCR Event objects.
Each ModeShape Repository instance has a ChangeBus component that is responsible for keeping track of all of the ChangeSetListeners and forwarding all of the ChangeSets to all those listeners. Multiple internal components send ChangeSet objects to it, and the bus forwards them to each listener. It is very important that this be done quickly and correctly. For example, one listener should never interfere with or block any other listeners. And, a listener should see all of the events in the same order in which they occurred.
If ModeShape is clustered, the ChangeBus satisfies the same requirements, but it works a little differently: when a component sends a ChangeSet, that ChangeSet is immediately sent via JGroups to all members in the cluster, and then in each process JGroups sends the ChangeSet object back to the ChangeBus, which in turn forwards it to all local listeners. By doing it this way, JGroups can ensure that all processes see the same order of ChangeSet objects.
Needless to say, the ChangeBus is critical and is also relatively complicated. The original design in 2.x evolved very little in 3.x, but as we’ll show, we’ve overhauled it completely for 4.0.
The ChangeBus in 2.x and 3.x
ModeShape 2.x and 3.x ChangeBus implementation used a fairly simple design: each listener had a “consumer” thread that ran continuously, popping ChangeSet objects from a listener-specific blocking FIFO queue and calling the actual listener. When a new ChangeSet is added to the bus, the ChangeBus adds that ChangeSet to the front of the queue for every listener.

Each listener thread consumes ChangeSet objects from its own blocking queue
This design had some nice benefits:
- The design is fairly simple.
- Every listener saw the same order of
ChangeSet objects.
- Each listener ran in a separate thread, so for the most part each was completely isolated from all other listeners (see below).
- Because of the blocking queues, if a listener were really slow and its queue was full, the
ChangeBus would block when trying to add the change set to the queue. This provided some backpressure to slow down the system (specifically the sessions making the changes) while the listener could catch up.
It also had a few disadvantages:
- When a
ChangeSet arrived, the bus had to iteratively add the ChangeSet to all of the listeners’ queues, and it did this before returning from the method. Of course, this takes longer when the bus has more listeners.
- A blocking queue has internal locks that must be obtained before a
ChangeSet can be added to it, and the consumer is also competing for this lock. This slows down the ChangeBus‘s add operation.
- The new
ChangeSet is added to the last listener’s queue only after the change set is added to all other queues. This introduces a time lag between the arrival of a ChangeSet in the ChangeBus and the delivery to the last listener, and this lag is more pronounced for those listeners that were added last (since they’re later in the list of listeners).
- If any of the blocking queues is full (because its listener is not processing the
ChangeSets fast enough), then the ChangeBus‘s add operation will block. This is good because it adds back pressure to the producer (specifically the sessions making the changes), but notice that the add operation is blocked before adding the change set into subsequent queues. So even if those listeners are caught up, they won’t see the change set until the listener with the blocked queue is able to catch up. This makes one listener dependent upon all other listeners that were added to the ChangeBus before it.
- Each listener’s queue maintains its own ordered copy of the list of
ChangeSet objects. More listeners, more queues.
Notice how having a larger number of listeners has a pretty big impact on the performance. We’ve already noticed a fair amount of lag with 3.x. And in the early pre-releases of 4.0 we’ve already added more internal listeners than we had in 3.x, and we plan to add even more for the index providers.
The new ChangeBus in 4.0
Back in the fall of last year, we knew that the old ChangeBus could be improved and talked about several possible approaches. One of the ideas discussed had a lot of potential: use a ring buffer.
A ring buffer is pretty straightforward. Conceptually it consists of a single circular buffer, one or more producers can add entries (in a thread-safe manner) into the buffer at a single cursor, and consumers trail behind the cursor and process (each in their own thread) each of the entries that are already in the buffer.
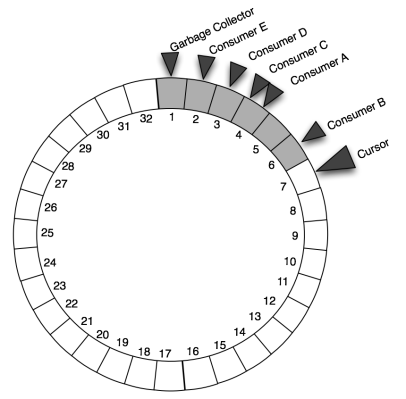
ChangeSets are added at the cursor, and consumer threads follow behind reading them
In the diagram above, the numbers represent the positions of entries in the buffer, starting at 1 and monotonically increasing. The cursor is at position 7, and there are consumer threads that are each reading a ChangeSet at a slightly different position: 6, 4, 3 and 2. Notice that there is a garbage collection thread that follows all other consumers, simply nulling out the ChangeSet reference after it has been consumed by all consumers. (We need this because the ring buffer typically has 1024 or 2048 slots, and this would consume lots of memory if every one had a ChangeSet with lots of changes. The ring buffer’s garbage collector enables all the already-processed ChangeSet objects to be garbage collected by the JVM.)
Here is another image of the ring buffer, after an additional 7 ChangeSet objects have been added and after enough time that the listeners’ consumer threads have advanced.
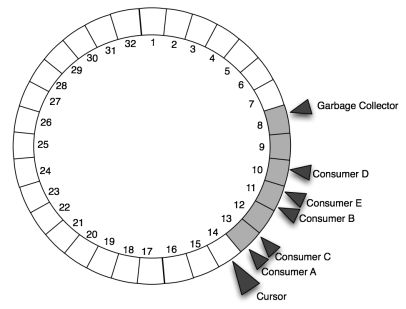
The cursor has advanced, as have all of the consumers and the buffer’s garbage collector
The position of each consumer is completely independent of all other consumers’ positions, though they are obviously dependent upon the cursor position where new entries are being added at the cursor. Typically the listeners are fast enough that the consumers trail very closely behind the cursor. But of course there will be variation, especially if the number of changes in each ChangeSet varies dramatically (and it usually does).
As more ChangeSet objects are added, the cursor advances and will get to the “lap” point, where it starts to reuse the entries in the buffer that were previously used. (Really, the buffer is a simple fixed-size Object[] that is allocated up front, and the positions in the buffer are easily converted into array indexes. We just visualize it as a ring.)
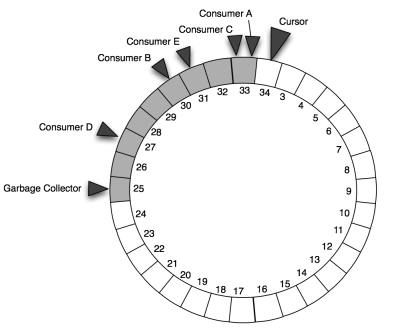
The cursor will eventually reuse buffer entries that are no longer needed
What happens if the cursor catches up to the garbage collector thread? First of all, the ring buffer is usually sized large enough and the listeners fast enough that this doesn’t happen. But if it does, the ring buffer prevents the cursor from advancing onto or beyond the garbage collector (which always stays behind the slowest consumer). Thus, the method adding a ChangeSet object blocks until the cursor can be moved.
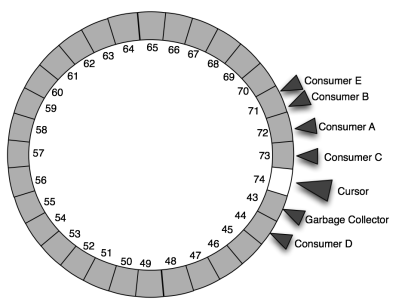
The cursor never “laps” the garbage collector or consumers, and this provides natural back pressure
In a real repository, this back pressure will mean a save operation takes a bit longer. And should this happen more frequently than you’d like, you always have the option of increasing the size of the buffer and restarting the repository. But really what this means is that your system doesn’t have enough cores to support the number of listeners, or that one or more of the listeners are simply taking too long and that perhaps you should consider using the JCR Event Journal instead of the listener framework. (With the event journal, your code can ask for changes that occurred during some period of time.)
At this level of detail it may look like the ring buffer has a lot of potential conflicts. But really, a good ring buffer implementation will maintain this coordination without the use of locks or synchronization techniques. Our implementation does exactly this: it uses volatile longs and compare-and-swap (CAS) operations to keep track of the various positions of the cursor, consumers and garbage collector, and the logic ensures that the consumers never get past the cursor’s position. In fact, we use the exact same technique and code to also ensure that the cursor never laps the garbage collector thread; after all, the buffer is a finite ring.
When all of the consumers are caught up to the cursor and no additional ChangeSet object has been added, then our implementation does currently make each consumer thread block until another ChangeSet object is added. This is done with a simple Java lock condition that is used only in this case; the condition never prevents the addition of a ChangeSet object.
In other words, a ring buffer should be fast. So we looked at various ring buffer implementations, including the LMAX Disruptor (which is very nice). While most of the features were great, there were a few characteristics of the Disruptor that weren’t a great match, so we quickly prototyped our own implementation.
A ChangeBus implementation that used the LMAX Disruptor was roughly an order of magnitude faster than our old one, and one that used our prototype ring buffer was even a bit faster. Given our implementation was small and focused on exactly what we needed, and that we didn’t need another third party dependency, we decided to turn our prototype into something that was more robust and integrated it into the 4.0 codebase. This new ChangeBus implementation will first appear in ModeShape 4.0.0.Alpha3.
This post was quite long, but hopefully you found it interesting and helpful. And for ModeShape users, maybe you’ll even have a bit more insight into how ModeShape handles events, and one of the many ways in which ModeShape 4 is improved.
Filed under: features, performance, techniques






